Meta AI语音模型 可识别4000种语言
面子书(Facebook)母公司(Meta)周二(5月23日)公布,旗下大规模多语言语音模型,可辨识超过4000种口语表达的语言,辨识量是既有技术的40倍;文字语音互转技术的应用范围,从100种语言增加至1100种,且可用于AR及VR。
世界上许多语言正面临消失的危机,而现有的语言辨识与生成技术上的限制更加快此趋势。Meta今天发布新闻稿指出,Meta发表一系列的AI模型,希望帮助用户以自己习惯的语言,更轻松获取资讯及使用电子装置。
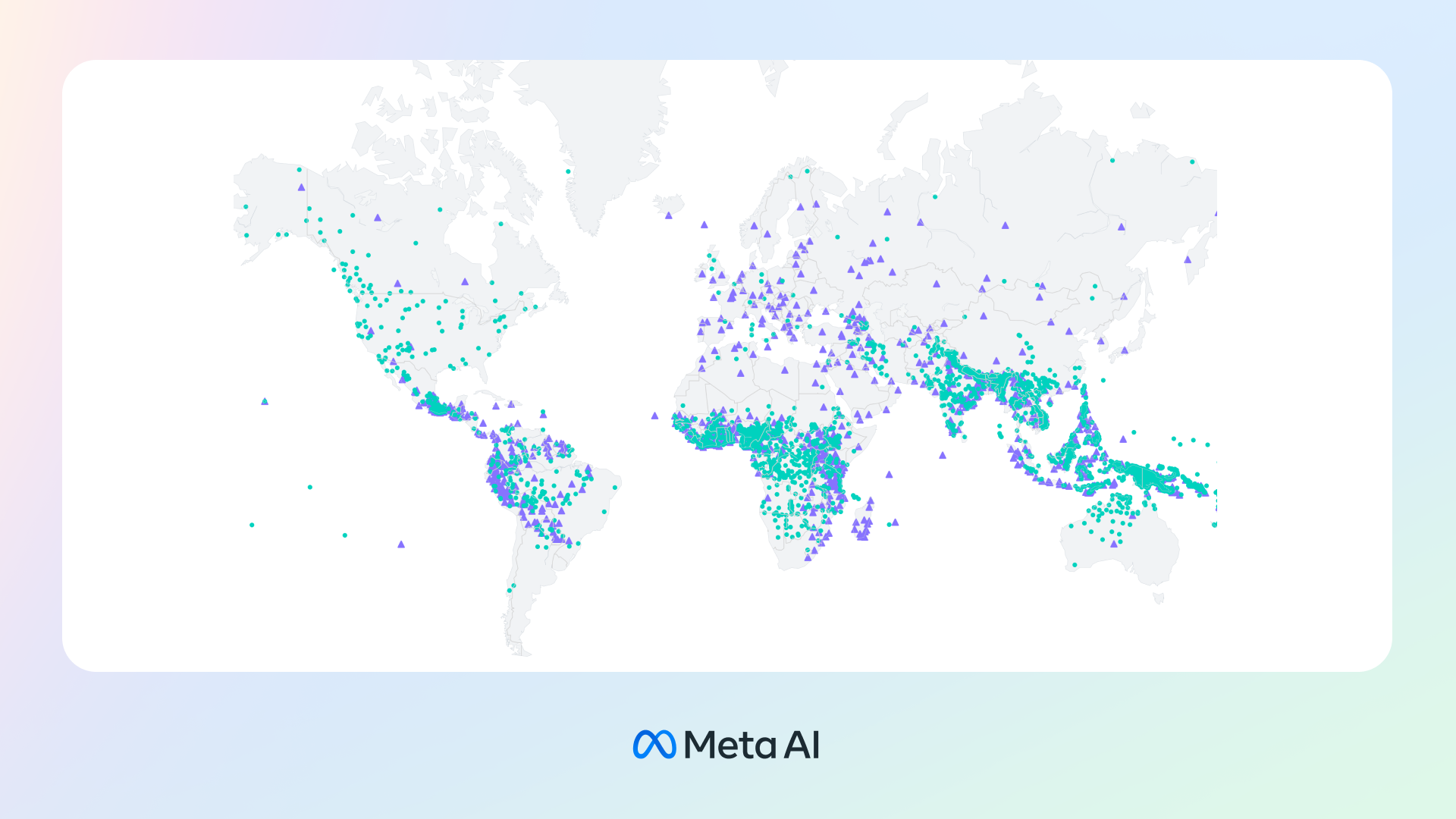
Meta表示,公司研发的大规模多语言语音(Massively Multilingual Speech,简称MMS)模型,扩展文字转语音及语音转文字技术的应用范围,从最初的100种语言,至今已可转换超过1100种语言,超越过去的10倍。还能辨识超过4000种口语语言,是过去的40倍。
应用案例方面,从VR(虚拟实境)、AR(扩增实境)至讯息服务,不仅能使用偏好语言操作,更可理解每个人的声音。
Meta指出,将开源这项技术的原始码及模型,让研究社群能够以现有的工作成果为基础继续开发,一同保存全球的语言,并拉近人们间的距离。
使用《圣经》作为训练文本
过去最大型的语音资料库最多仅涵盖100种语言,因此开发此技术所面临的第一个挑战即为“搜集数千种语言的语音训练资料”。为了克服这项挑战,Meta使用已翻译成多种语言、译文已被广泛阅读及研究的宗教经典,例如《圣经》,作为语言的文字训练资料。


Meta表示,圣经译文有多种语言的公开录音档,作为大型多语言语音模型计画的一部分,Meta创造的资料集,搜集超过1100种语言的《新约圣经》有声读物资料集,平均为每种语言提供32小时的语音训练资料,后续又加入其他未标注的基督教有声读物后,可用的语言训练资料已涵盖超过4000种语言。
Meta强调,将持续扩增大规模多语言语音模型的涵盖范围,以支援更多语言的转换及辨识,并努力克服现有语音技术难以处理方言的挑战。